

Własna baza NoSql – gramatyka, parser, lekser
Cześć,
chyba powoli pewną tradycją staje się zaczynanie wpisu od „dawno tu nie pisałem” – nie inaczej jest i dziś – no więc dawno tu nie pisałem, ale za to dziś wracam z bardzo ciekawym zagadnieniem a dokładniej z wprowadzeniem do pisania własnego języka programowania – czyli tego czym jest gramatyka języka, jak ją tworzyć i jak z niej generować takie „byty” jak parser i lekser.. I co to w ogóle jest ten parser i lekser:)
Zacznijmy od samego, samego, sameeeegooo początku.
Każdy kawałek kodu, dosłownie każdy, w ostatecznym momencie swojego wykonania jest pewną sekwencją 0 i 1 odpowiednio interpretowanych przez procesor. Tzn że pisząc w obojętnie jakim języku, paradygmacie czy framework’u – zawsze na sam koniec komputer dostaje ten ciąg 0 i 1. To jest kod maszynowy.
Wyżej mamy Assemblera – czyli język który operuje tylko na instrukcjach samego procesora i on będzie generował kod maszynowy.
Jeszcze wyżej są już kompilatory które muszą w wyniku wymyślonej przez siebie drogi – dojść do kodu maszynowego. Tak np. C/C++ działa na Assemblerze ale już Java kompiluje swój kod do kodu pośredniego i ten kod jest uruchamiany na maszynie wirtualnej Javy – i to ona zapewnia możliwość uruchomienia jej na dowolnej architekturze procesora. Rozwiązanie które wymyślili twórcy Javy mają jedną zaletę – przenośność kodu, bo np. jeśli skompilujesz program w języku C na procesorze 32bitowym to nie uruchomisz go na procesorze 64bitowym.
Istotną rzeczą którą napisałem wyżej jest wymyślonej przez siebie drogi – oznacza to że nikt nie zabroni nam napisać programu w np. Pythonie który będzie generował kod do Pythona i dopiero go uruchamiał:)
No więc wstęp mamy za sobą. W tym co napisałem wyżej jest pewien skrót myślowy który trzeba rozwinąć – a dokładniej nadal pokręcimy się w okół tej „drogi” którą przebiega program napisany w języku A do momentu dojścia do kodu maszynowego, no bo jak każdy wie, języki programowania narzucają nam pewną składnię pisania programów oraz odpowiednio ją interpretują. Opowiem więc skąd np. kompilator Javy wie że ma rzucić błąd składniowy jeśli nie postawimy średnika albo skąd wie że słowo „if” jednoznacznie implikuje instrukcję warunkową i wie że ma dalej oczekiwać jakiegoś wyrażenia.
No więc lecimy!
Wyobraź sobie kawałek kodu, np. w Pythonie:
1 2 3 4 | if 11>10: print("yes") else: print("no") |
-
Sprawdzeniem czy kod nie zawiera niedozwolonych znaków (i ewentualne ich usunięciem).
-
Pogrupowanie znaków w jednostki leksykalne – tokeny ; przez token rozumie się przeważnie grupę znaków odseparowaną od pozostałych białymi znakami (spacja, tabulator, nowa linia)
-
Rozpoznanie tokenów, wyróżnienie słów kluczowych, operatorów, łańcuchów znakowych
-
Stworzenie tablicy tokenów, przechowującej tokeny i informacje o nich
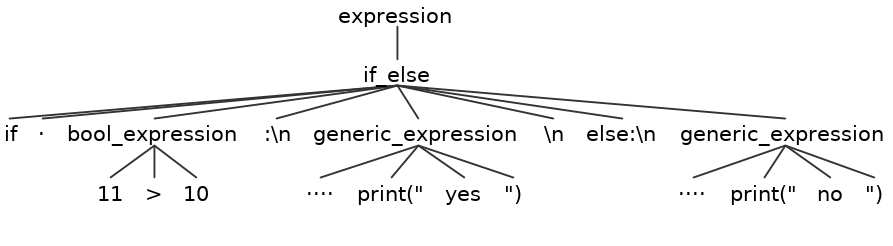
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | grammar python_if; expression : if_else ; if_else : 'if' SPACE bool_expression ':\n' generic_expression '\n' 'else:\n' generic_expression ; bool_expression : NUMBER '>' NUMBER ; generic_expression : SPACE 'print("' STRING '")' '\n'* ; NUMBER : [0-9]+ ; SPACE : ' '+ ; STRING : [a-zA-Z]+ ; |
-
Pierw spodziewam się słowa „if”…
-
Następnie powinien być token SPACE który jest zdefiniowany jako „co najmniej jedna spacja”…
-
Następnie powinien być token „bool_expression” zdefiniowany jako „co najmniej jedna cyfra z przedziału 0-9”, znak '>’ i znów „co najmniej jedna cyfra z przedziału 0-9″…
-
Następnie powinien być znak nowej linii…
-
Następnie (jesteś w ifie – warunek spełniony) wyrażenie tutaj nazwane „generic_expression” i jest zdefiniowane jako „co najmniej jedna spacja” ciąg 'print(„’ „co najmniej jedna duża lub mała litera alfabetu” ciągi '”)’ dalej jest znak nowej linii w ilości dowolnej (także zero)…
-
Następnie szukamy znaku nowej linii, słówka 'else:’ oraz znów znaku nowej linii…
-
Następnie szukamy znów generic_expression – czyli naszego print’a.
1 2 3 4 | if a>10: print("yes") else: print("no") |
1 | line 1:3 mismatched input 'a' expecting NUMBER |
 Jak takie parsowanie działa od strony algorytmu? Ano mniej więcej tak:
Jak takie parsowanie działa od strony algorytmu? Ano mniej więcej tak:
Parsery parsują znak po znaku, utrzymując stos zawierający „spodziewane symbole”. Na początku znajdują się tam symbol startowy i znak końca pliku. Jeśli na szczycie stosu jest ten sam symbol terminalny, jaki aktualne znajduje się na wejściu, usuwa się go ze szczytu stosu i przesuwa strumień wejściowy na kolejny znak. Jeśli inny symbol terminalny zwraca się błąd. Jeśli występuje tam jakiś symbol nieterminalny, to zdejmuje się go i zależnie od tego symbolu oraz od k kolejnych znaków wejścia, umieszcza na stosie odpowiedni zestaw symboli.
Parser o którym piszę to LL(1) czyli taki co analizuje tekst od lewej do prawej i produkujący lewostronne wyprowadzenie metodą zstępującą – nie jest nam bardzo potrzebne już co do dokładnie znaczy – ale internet stoi dla Ciebie otworem:)
Teraz już trochę praktycznej praktyki – gramatyka którą Ci przedstawiłem jest zgodna z biblioteką ANTLR która pozwala wygenerować parser i lekser dla zadanej gramatyki i odpowiednio go użyć:) Możesz sobie poczytać na stronce o niej.
Kończąc tę pierwszą cześć muszę napisać jeszcze czego będzie dotyczyć druga część – ta już bardzo praktyczna – ano stosując analizę leksykalną oraz syntaktyczną zbudujemy własną bazę NoSql inspirowaną (mocno :)) Redisem. Oczywiście w Pytonie. So.. Stay tuned! EDIT: Druga cześć już ukończona! Przeczytaj!
Mateusz Mazurek






