

Maintenance – jak to ugryźć?
Cześć, dziś nieco mniej technicznie, bo dziś napisze kilka słów o utrzymywaniu oprogramowania.
Ogólnie utrzymanie oprogramowania sprowadza się do robienia wszystkiego by ono działało i by klienci byli jak najbardziej zadowoleni z tego jak działa. To zadanie niesie za sobą całkiem sporo – od zapewnienia uptime’u aplikacji (infrastruktura sieciowa, serwerowa i aplikacyjna) przez jej wydajne działanie, aż do dążenia do stanu aplikacji gdzie działa ona bezbłędnie.
Utrzymanie niesie za sobą bardzo dużą dozę odpowiedzialności, no bo jakby porównać tę pracę do pracy przeciętnego developera to jego działania, tj. nowy kod, przechodzi przez kilka osób nim dotrze na produkcję – co znacznie zmniejsza ryzyko wypuszczenia do klienta czegoś co nie działa / psuje system. Developer nie zarządza też danymi klientów, więc nie ma problemów typu „zrobiłem UPDATE’a bez WHERE”, a także nie stara się wychodzić im na przeciw – przeciętny developer dostaje specyfikację i wg niej tworzy jakąś funkcjonalność, oczywiście najlepiej jak potrafi oraz tak by było łatwo to utrzymać.
No ale w takim razie jak wygląda praca utrzymaniowa? Otóż tutaj stykamy się z nieprzeciętnymi case’ami działania aplikacji – gdyż te trywialne zostały już przewidziane przez project managerów, ewentualnie w późniejszym etapie – developerów lub wynikły z sugestii działu zachowania jakości. Case’y które spotykam najczęściej są wynikiem baaardzo nie sprzyjającego środowiska – czyli takie gdzie należy mocno zastanowić się co, nie do końca logicznego/przewidywalnego, zrobił klient. Przykład:
– klient wylogował się podczas trwania innej operacji, która ogólnie jest zabezpieczona przed takim case’em, ale zrobił to na tyle szybko że zabezpieczenie nie mogło zadziałać,
– klient wykorzystał nieszczelność systemu i wyklikał coś co nigdy nie powinno było się wydarzyć i nigdy nie miało prawa działać,
– nie załadował się cały JavaScript (np. problem z internetem) i udało mu się wypełnić pole tekstowe zakazaną wartością i nie fartownie akurat tam walidacja w backendzie nie zadziałała,
– nie załadował się cały JavaScript i tylko część żądań AJAX się wykonała co spowodowało rozstrojenie systemu.
itp.
Ale to tylko wierzchołek góry. Poza analizą nietrywialnych przypadków produkcyjnych jest jeszcze trzymanie pieczy nad spójnością bazy danych. A więc jeśli klient w wyniku błędnego działania systemu wprowadził system w stan nieustalony – naszym zadaniem jest naprostowanie tego, a więc jeśli chodzi o bazę danych, taka modyfikacja danych by one zaczęły nabierać sensu. I tutaj potrzebna jest precyzja chirurga. Każdy zapomniany warunek może doprowadzić do ogromnych problemów a nawet całkowitego wstrzymania działania aplikacji. W tym miejscu należy wykazać się również bardzo dobrą znajomością schematu bazy danych i/lub sprawnym czytaniem SQLek w kodzie. Warto tu wspomnieć, że zależnie od organizacji, zmiany na bazie danych klientów, mają swój, mniej lub bardziej złożony proces i mniej, lub bardziej rozbudowaną listę ludzi, którzy mogą to zrobić. Np. w niektórych firmach bardzo mało osób ma dostęp do danych produkcyjnych, ale nie ma większego procesu uruchamiania SQLek, no może, poza „ej, możesz mi spojrzeć na ręce?”. Natomiast gdzie indziej ilość osób jest znacznie większa ale np. każda zmiana, a więc każde wykonanie jakiegokolwiek kodu SQL jest opakowane w swoisty „sandbox”, który podnosi poziom bezpieczeństwa tych SQLek np. robiąc kopię zapasową zmienianych wierszy i ewentualnie ją przywracać w przypadku jakiegoś wyjątku. Pisząc sandbox mam na myśli że SQLkę nie wykonuje po prostu osoba, a skrypt, który zapewni jej bezpieczeństwo. Nie ma się co spierać, który model jest lepszy – każda organizacja wypracuje własny.
Idąc w dół – poza robieniem hotfixów (zmian w kodzie na produkcji) i datafixów (zmian na bazie danych) jest jeszcze ogólnie wspieranie klienta. A więc rozwiązywanie problemów typu:
– o nie, skasowałem sobie obiekt A! I nie mogę przywrócić!
– o nie, chce zaimportować 500000 wierszy – a limit jest do 200000 – co ja pocznę?
itp.
Idąc jeszcze dalej – utrzymanie to zapewnienie braku problemów z dostępnością aplikacji. Oczywiście na pewnym poziomie abstrakcji, bo gdybym musiał zapewnić dostępność na każdym poziomie architektury – to jednak sorry, ale braknie mi i wiedzy i czasu. Ale zdarza się rozwiązywać problemy typu:
– deadlocki na bazie danych
– długie transakcje na bazie
– awarie demonów
itp.
Fakt, że masz dostęp uprzywilejowany do zasobów produkcyjnych wiąże się z pewną dozą presji. Jeśli klientowi coś nie działa, potrafi on dzwonić/pisać i popędzać na prawdę często. I w gruncie rzeczy ciężko się dziwić.
Poziom presji jest również nieco zależny od tego jaką drogą przyjdzie zgłoszenie. Po prostu jedni ludzie bardziej rozumieją, że pewne rzeczy muszą trwać, inni mniej. Presja jest o tyle zła, że odcina dostęp do części wiedzy którą w sytuacjach normalnych jak najbardziej się posiada – przez co może prowadzić to do większej ilości pomyłek podczas interwencji. Osobiście uważam, że najlepszym rozwiązaniem jest nie poddawać się presji na tyle na ile jest to możliwe i po prostu robić swoje najlepiej jak się umie. Oczywiście mając na względzie, że trzeba to zacząć robić od razu, a nie iść po kawę.
Obusiecznym mieczem w tej grze jest SLA. Termin ten rozwija się do Service Level Agreement i spłaszczając – określa jak szybko mamy pomóc klientowi z jego problemem. I czasem jest dla nas argument mówiący „to może zaczekać do jutra” jeśli SLA przewiduje to. Ale czasem jeśli jest krótkie – każe nam wziąć się za problem od razu.
Aby dobrze utrzymywać aplikację musimy znać cały system albo chociaż wiedzieć do kogo kierować pytania w obszarach które znamy słabiej. Jest to bardzo ważne gdyż poszczególne elementy systemu ze sobą współpracują i nie ma najmniejszej możliwości sprawnego debugu bez znajomości zależności pomiędzy komponentami. Istotną wiedzą jest też w jaki sposób komponenty się ze sobą komunikują i mam na myśli nie tylko interfejs ale też technologię komunikacji, która może być zrealizowana na kilkanaście różnych sposobów – od HTTP, TCP przez Unix Sockets, ZeroMQ, RabbitMQ aż do Redisa czy rozwiązania typowo bazodanowego – i każda ma swoje wady i zalety i powinna być dobrana już na etapie developmentu, gdzie jednym z czynników decydujących powinna być łatwość utrzymania owego rozwiązania.
Aby móc debugować problemy każdy z komponentów powinien posiadać swoje logi. A wiec możliwie najdokładniejszy zapis historii jego poczynań. Jeśli komponent jest wielowątkowy każdy wątek powinien prezentować się w logach jakimś unikalnym ciągiem znaków żeby łatwo było wyciągnąć cały przebieg, gdyż w takim przypadku wpisy w logach będą się przeplatały pomiędzy wątkami. A wiec log nie powinien wyglądać tak:
1 2 3 4 5 6 7 8 | Waiting for data Waiting for data Data received Data received Collected data: {'id': 12345} Collected data: {'id': 92225} Error validaton! Processing data for input... (args 12332) |
ponieważ jest całkowicie niejednoznaczny. Widzimy tu, że najpierw dwa wątki oczekują na dane. Potem oba dostają różne dane i jeden się wywala na walidacji, a drugi zaczyna kolejny proces przetwarzania. Ale nie wiemy… Który się wywalił! Dobrze by było poprawić te logi by wyglądały tak:
1 2 3 4 5 6 7 8 | 2018-03-10 19:10:21 32432fffdsf42 Waiting for data 2018-03-10 19:10:21 78926567dsfsd Waiting for data 2018-03-10 19:10:22 32432fffdsf42 Data received 2018-03-10 19:10:25 78926567dsfsd Data received 2018-03-10 19:10:26 78926567dsfsd Collected data: {'id': 12345} 2018-03-10 19:10:27 32432fffdsf42 Collected data: {'id': 92225} 2018-03-10 19:10:27 78926567dsfsd Error validaton! 2018-03-10 19:10:27 32432fffdsf42 Processing data for input... (args 12332) |
Co pozwala na pierwszy rzut oka zobaczyć, że wywalił się task z id równym 12345. Oczywiście one nadal są dalekie od doskonałości, gdyż brak jakiejkolwiek informacji czemu walidacja się nie udała itp, ale chciałem pokazać ten aspekt demonów wielowątkowych.
Jak napisałem wyżej – logi powinny być możliwie najbardziej szczegółowe, ale jednocześnie proste. Należy unikać w nich niejednoznacznych skrótów gdyż będzie to czasem wymagało szukania po kodzie wywołania loggera i przeanalizowania co skrót oznacza, a to niepotrzebnie zwiększa czas debugu. Przy konstruowaniu logów powinno się pamiętać by były one w jedynym słusznym języku – angielskim – gdyż nigdy nie wiesz kto i kiedy będzie w przyszłości utrzymywać ten system.
Każdy wpis powinien być opatrzony datą i godziną. Najlepiej z częścią milisekundową. Istotnym info jest też kiedy ten wpis się pojawia – czy po zakończeniu operacji, którą opisuje czy przed nią. Np. access.log Lighttpd pokazuje daty zakończenia requestów.
W dobrym tonie jest też informacja do logów jak demon startuje i jak się zakańcza. Samo uruchomienie powinno nieść też ze sobą info o konfiguracji jakiej będzie demon używał.
Poza tym ilość informacji jakie komponent loguje powinna być konfigurowalna tak zwanym poziomem logowania. Poziomów istnieje kilka:
Level Description
ALL All levels including custom levels.
DEBUG Designates fine-grained informational events that are most useful to debug an application.
ERROR Designates error events that might still allow the application to continue running.
FATAL Designates very severe error events that will presumably lead the application to abort.
INFO Designates informational messages that highlight the progress of the application at coarse-grained level.
OFF The highest possible rank and is intended to turn off logging.
WARN Designates potentially harmful situations.
a więc w kodzie możemy zrobić np:
1 2 3 4 5 | log.debug("Debug Message!"); log.info("Info Message!"); log.warn("Warn Message!"); log.error("Error Message!"); log.fatal("Fatal Message!"); |
Każdy komponent powinien mieć ustawiony poziom logowania inny dla uruchomienia produkcyjnego i inny dla developerskiego. A więc jeśli na produkcji włączymy poziom logowania:
- WARN to dostaniemy logi z poziomu WARN, ERROR i FATAL
- DEBUG to zobaczymy DEBUG, INFO, WARN, ERROR, FATAL
zgodnie z tym wzorem:
1 | ALL > DEBUG > INFO > WARN > ERROR > FATAL > OFF |
Idealnie na produkcji poziom powinien być WARN a developersko ALL, wynika to z tego że pliki logów na produkcji przy wysokim poziomie logowania mogą zajmować bardzo dużo miejsca na dysku.
Często zdarza się, że mimo wszystko decydujemy się na wyższy poziom logowania produkcyjnego – ponieważ pozwala on zbierać więcej informacji o tym co demon robi.
Praca utrzymaniowa czasem wymaga reakcji natychmiastowych. Najczęściej w sytuacjach jawnych błędów w kodzie – kiedy to klient zgłasza, że coś nie działa. Wtedy pierwszą rzeczą jaką robimy jest sprawdzenie logów gdzie pewnie odnajdziemy stacktrace(lista wywołań funkcji i komunikat wyjątku) z błędem.
I gdy dojdziemy do tego co powoduje błąd jest kilka sposób na poradzenie sobie z tym:
1. Możemy otoczyć kawałek kody blokiem try-catch – i dobrze obsłużyć wyjątek.
2. Możemy wyłączyć funkcjonalność jeśli nie jesteśmy w stanie sprawnie poprawić kodu, np. poprzez
1 | return False |
3. Możemy przyjąć wartość domyślną dla problematycznego kawałka kodu.
4. Możemy rzutować czy posłużyć się sprytnym IFem.
5. Możemy po prostu wprowadzić poprawkę, która rozwiąże na daną chwilę problem.
Oczywiście to tylko przykłady rozwiązań i każde rozwiązanie należy dobrać do aktualnie zaistniałeś sytuacji.
Co tu jest ważne to czas. Awaria na produkcji to nie czas na docelowe rozwiązane, a na umożliwienie pracy klientowi. Dopiero jeśli umożliwimy to i klient potwierdzi, że system znów działa stabilnie, możemy przystąpić do implementacji docelowej – zgodnej ze sztuką i dobrymi praktykami programistycznymi. Taka interwencja nazywa się hotfixem, którego terminu użyłem już wcześniej.
Oczywiście nie zawsze jesteśmy w stanie przywrócić system do życia bez popsucia go na chwilę bardziej – możliwe że będzie potrzebny restart jakiejś części systemu lub całkowite zepsucie aktualnego stanu systemu co może spowodować potrzebę przelogowania użytkowników klienta. Aczkolwiek zgodnie z zasadą „skoro nie działa to ciężko żeby nie działało bardziej” – możemy to zrobić, oczywiście jeśli jest to konieczne. Tutaj znów należy wiedzieć co dla klienta jest ważne i taką informację powinna dostarczyć osoba zgłaszająca problem.
Od czasu do czasu zdarzy się sytuacja gdzie aktualnie posiadane logi są niewystarczające. Wtedy stosuje się metodę powszechnie znaną jako 'dupa-debugging”.
Polega ona ma dodawaniu w kodzie loggerów które pokazują nam przebieg wykonywania się kodu, np. poprzez:
1 | logger.debug("dupa1") |
dodane przed IFem oraz
1 | logger.debug("dupa2") |
w IFie. Dla przykładu:
1 2 3 4 5 | if (metodaZwracającaMagicznieBooleanKtórejNiktNieOgarnia()){ System.out.println("dupa1"); }else{ System.out.println("dupa2"); } |
Takie coś pozwala potwierdzić/obalić przypuszczenia związane z tym jak faktycznie kod działa. Słowo „dupa” się stosuje ponieważ jest ono krótkie – a jak wiadomo – liczy się czas. Oczywiście nikt nie każe używać „dupa” cały czas, wynika to z tego że te logi nie są logicznie związane z kodem więc wystarczy tam wpisać coś co będzie wyróżniało w logach. Równie dobre będzie „AAAAA”. Oczywiście stosuje się to wtedy kiedy nie można postawić zdalnego debuggera. Aczkolwiek debuggując produkcję nigdy nie będzie można tego zrobić chociażby dlatego że spowalnia on działanie aplikacji.
Obok hotfixów są jeszcze datafixy o których już jakiś czas temu wspomniałem. Są to operacje na bazie danych mające na celu uzupełnienie brakujących danych lub przywrócenie jej do stanu ustalonego. Zazwyczaj datafixy są konieczne w przypadku kiedy kod z jakiegoś powodu nie wypełni tabel odpowiednimi danymi lub w wyniku większej awarii część danych została utracona/uszkodzona. Datafixy możemy sami robić lub generować. Zazwyczaj ciężko jest napisać kawałek kodu który będzie na tyle generyczny że pozwoli nam wygenerować np. dokładnie takie inserty jakie w aktualnym momencie potrzebujemy.
Załóżmy że mamy tabelkę która ma 4 kolumny:
1 2 3 4 5 6 7 8 9 | CREATE TABLE public.table1 ( id serial, name CHARACTER VARYING, VALUE CHARACTER VARYING, created_at TIMESTAMP WITHOUT TIME zone, created_by BIGINT, CONSTRAINT id_pk PRIMARY KEY (id) ) |
i legenda:
kolumna name to złączenie słowa „adm” z wartością kolumny value. Created_at to aktualna data i godzina i created_by to id użytkownika który robił wpis.
Dla naszego przykładowego datafixa niech wartości które powinny zostać wrzucone do bazy mają wartość:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | 86275 59988 67610 38931 31269 20432 76948 47588 93401 27916 94987 36720 56541 53806 59144 23797 84253 71254 66204 14677 66839 60186 26265 58808 92060 26263 22453 50080 54454 81134 |
kolumna created_at musi być spójna z całą bazą danych i dla tego przypadku musi mieć wartość o 2h wcześniejszą niż aktualna datogodzina. Created_by powinno mieć stałą wartość użytkownika systemowego: -1.
Osobiście używam najczęściej czegoś półautomatycznego. Żeby wygenerować proste SQLki używam Visual Studio Code.
I jeszcze dodać pomiędzy wygenerowanymi INSERTami „begin” i „commit” co pozwoli wprowadzić dane w jednej transakcji. To bardzo ważne. Bo jeśli np. 10 pierwszych INSERTów uda się dodać a 11 spowoduje błąd, to bez transakcji będziemy musieli pamiętać aby nie dodawać tych pierwszych 10ciu a tylko pozostałe 20. Z transakcją po prostu przy drugiej próbie jeszcze raz wykonujemy całą SQLkę.
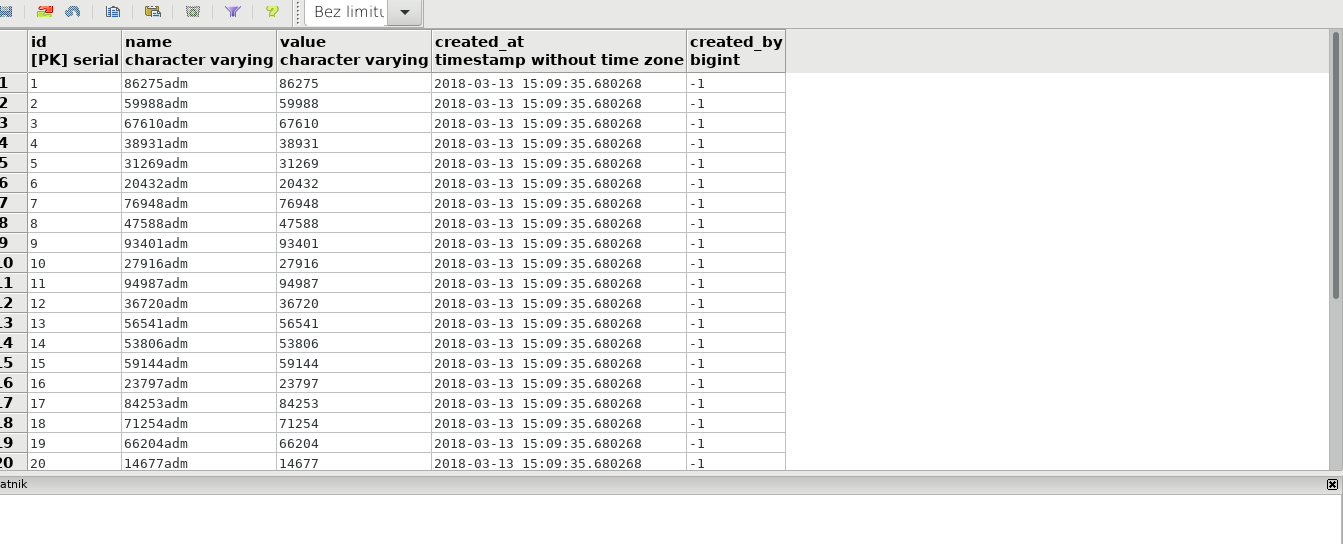
W naszym przypadku udało się wykonać wszystkie INSERTy:
Z doświadczenia wiem że wygenerowane IDki czasem są potrzebne dalej – i w przypadku postgresa możemy łatwo uzyskać wygenerowany ID z INSERTa:
Stwórzmy teraz drugą tabelkę:
1 2 3 4 5 6 7 8 9 10 | CREATE TABLE public.linked ( tables1_id bigint, "desc" character varying, CONSTRAINT id_fk FOREIGN KEY (tables1_id) REFERENCES table1 (id) ON UPDATE NO ACTION ON DELETE NO ACTION ) WITH ( OIDS = FALSE ) ; |
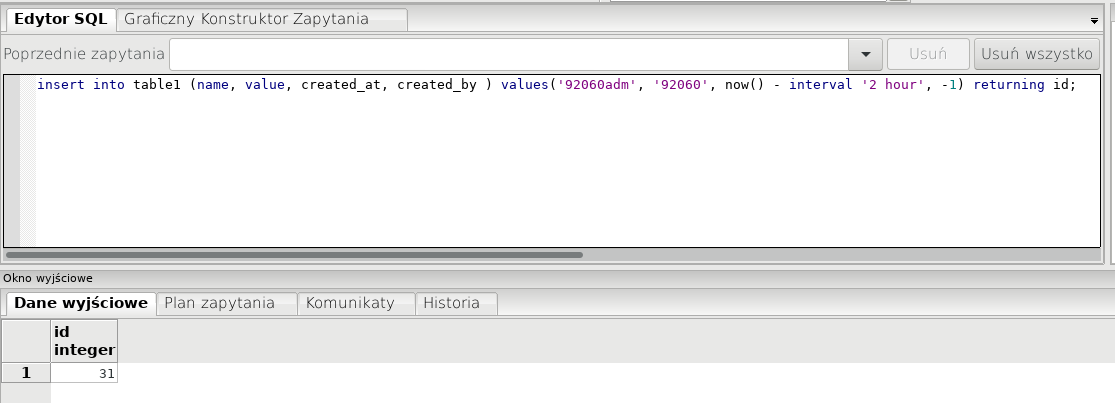
Jak widać tables1_id jest kluczem obcym z odniesieniem do kolumny id w table1. I teraz zadaniem jest wrzucenie do tabelki table1 wartości i do tabelki linked wpisów powiązanych z wrzuconym IDkiem. Podejść jest kilka…
Jedno z nich to zrobić to z użyciem bloku anonimowego:
1 2 3 4 5 6 7 | DO $$ DECLARE lastid INTEGER; BEGIN INSERT INTO table1 (name, VALUE, created_at, created_by ) VALUES('92060adm', '92060', now() - INTERVAL '2 hour', -1) returning id INTO lastid; INSERT INTO linked (tables1_id, "desc") VALUES (lastid, 'jestę opisę'); END $$; |
Gdzie po prostu zapisujemy sobie zwrócone ID i korzystamy z niego dalej. To podejście wymaga wygenerowania sobie takiego bloku dla każdego INSERTa – korzystając z Visual Studio Code nadal jest to proste. Innym rozwiązaniem może być trigger na tabelce table1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | CREATE OR REPLACE FUNCTION after_insert_table1_func() RETURNS TRIGGER AS $BODY$ BEGIN INSERT INTO linked (tables1_id, "desc") VALUES (NEW.id, 'jestę opisę'); RETURN NEW; END; $BODY$ LANGUAGE plpgsql VOLATILE COST 100; ALTER FUNCTION after_insert_table1_func() OWNER TO postgres; CREATE TRIGGER after_insert_table1 AFTER INSERT ON table1 FOR EACH ROW EXECUTE PROCEDURE after_insert_table1_func(); |
który pozwoli w łatwy sposób wypełnić tabelkę zależną. To rozwiązanie jest o tyle lepsze że wystarczy wygenerować sobie same INSERTy. A samego triggera można wyłączyć po wykonaniu datafixa i włączać w razie potrzeby.
Lwią częścią utrzymania są powtarzalne procesy które należy automatyzować. Jeśli jesteś tym szczęściarzem i pracujesz na linuxie masz ogrom możliwości automatyzacji pracy.
W linuxie na początek dostajesz terminal ze starym dobrym bashem. I jakby sobie w tej konsoli popisać to możesz popisać… I tylko to. Zobacz wiec co potrafi Terminator.
Na początek Terminator pozwala na dzielnie okna na kilka terminali z czego każdy jest osobną konsolą – wygodne jeśli robisz kilka rzeczy na raz albo jak przeglądasz logi kilku aplikacji próbując zestawić czasy. Poza tym feature’em – możemy jeszcze robić zakładki z kolejnymi konsolami – pozwala to nie tracić czasu na przełączanie się pomiędzy oknami.
Koleją super rzeczą jest możliwość tzw. grupowania terminalni – czyli pisania na kilku naraz tego samego. Używam czasem jak chce zrobić na kilku produkcjach to samo a pisanie playbooka wydaje się być wolniejsze.
Linux, jak napisałem wcześniej, dostarczam nam powłokę bash. Jest ona funkcjonalna, aczkolwiek, można mieć lepszą :) ja używam fish’a – https://fishshell.com/
Przede wszystkim przydaje mi się w nim podpowiadanie komend użytych wcześniej i działa to w dość inteligentny sposób – tzn fish pamięta że komenda zaczynając się na 'as’ użyta będąc w folderze o nazwie „admin” była inna niż kiedy byliśmy w home’ie – i podpowiada tę właściwą! W dodatku fish dodaje kolory – co nieco ułatwia poruszanie się po konsoli a klawiszem tab mogę uzyskać listę wszystkich plików w folderze lub binarek znajdujących się w PATHie. Oczywiście zaczynających się od wpisanego prefixu ;)
Zapraszam do przejrzenia tutoriala fisha bo warto – https://fishshell.com/docs/current/tutorial.html#tut_why_fish
Oczywiście fish nie jest jedynym „bash’em na sterydach” – istnieje kilka alternatyw i raczej jest to kwestia przyzwyczajenia niż faktycznej walki o to która powłoka jest lepsza. Samego fish’a można jeszcze bardziej rozwinąć dzięki projektowi omf – czyli oh-my-fish. Dostarcza on możliwość instalowania dodatkowych pluginów i templatek – rozszerzających możliwości samego fisha oraz zmieniających jego kolory czy usytuowanie informacji np. o aktualnym katalogu czy gałęzi (o ile jesteśmy w folderze z repozytorium).
Zarówno fish jak i bash mają możliwość tworzenia aliastów czyli skrótów do bardziej zaawansowanych komend.
Np. Zakładając że mamy w folderze /usr/virtualenvs/local/dev1 python’owego virtualenva i chcemy się do niego przesource’ować – musimy wpisać:
1 | source /usr/virtualenvs/local/dev1/bin/activate |
Trochę długie… Więc skróćmy to tworząc alias:
1 2 | alias dev1="source /usr/virtualenvs/local/dev1/bin/activate" funcsave dev1 |
gdzie pierw tworzymy alias a potem go zapisujemy (coś ala dodanie do .bashrc). I możemy od tego czasu używać aliasu dev1 do przesource’owania się.
Aliasy mogą być tworzone oczywiście do plików sh w których już można napisać wszystko.. I doprowadzić do tego że całe środowisko stawia się jednym poleceniem np ;)
Czasem zdarza się potrzeba zrobienia czego bardziej skomplikowanego jak na basha i wtedy warto użyć interpreterów „adhoc” języków typu PHP czy Python. Jako że ja częściej siedzę w Pythonie to i tego właśnie języka używam. Siłą tego narzędzia jest to że tu możesz mieć ładny, wysokopoziomowy dostęp chociażby do bazy danych. Standardowo to co dostajemy po zainstalowaniu Pythona jest dość ubogie i niewygodne, ale Internet już sobie z tym poradził i stworzył projekt bpython – https://bpython-interpreter.org/ – podpowiada on składnię oraz ją koloruje. Poza tym ułatwia dostęp do dokumentacji i pozwala używać ostatnio wykonanych linijek ponownie.

Przy administracji serwerami, co nierzadko jest koniecznie, poza wspomnianym wcześniej grupowaniem okien – świetnie sprawdza się Ansible. Nie będę jednak powielał wiedzy – odsyłam do poprzedniego wpisu Ansible – zarządzanie serwerami.
Przydatnym narzędziem są też małe programiki które sobie człowiek pisze gdzieś na kolanie. Polecam użyć biblioteki Fire – GitHub – pozwala ona łatwo użyć większości napisanych funkcji w formie komend w linii poleceń, obsługując przy tym błędy i trzymając pieczę nad argumentami do funkcji.
Oczywiście warto czasem interweniować zanim klient zgłosi problem – ale do tego jest potrzebny system wczesnego powiadamiania o anomaliach. Monitorować żywotność serwerów i stan aplikacji można dzięki Zabbix’owi – otwartoźródłowemu oprogramowaniu – może on wysyłać maile z informacją np. o niespodziewanym skoku użycia pamięci czy o braku miejsca na dysku. Same błędy aplikacji w najprostszym wydaniu można przekierować na maila – sprawdza się to ogólnie. Ostatnio staram się przekonać do Sentry – aplikacji pozwalającej ładnie segregować i zarządzać powiadomieniami o błędach – Sentry.
Wszystko o czym tu piszę wymaga wiedzy na temat działania systemu. Jak zacząć gdy idziesz do pracy i każą Ci utrzymywać aplikację którą pierwszy raz widzisz na oczy? Anooo…
Wiele tu zależy od ludzi. Pierwsze od czego bym zaczął to od poznania możliwie najbardziej dziedziny problemu – to jest do czego dokładnie aplikacja służy, jaki problem rozwiązuje. Jakimi ludźmi są odbiorcy aplikacji. Kolejny krokiem jest oczywiście „przeklikanie” się przez aplikację i tutaj spokojnie możesz się nią bawić nawet cały dzień. Warto również mieć ją postawioną lokalnie (polecam Dockera). Gdy to już umiesz to powinieneś dostać kilka łatwych rzeczy do poprawienia, całkowicie bez terminu – niech to zajmie tyle ile potrzeba. Proś o „patrzenie przez ramię”, o tłumaczenie itp. Naucz się używać już dostępnych narzędzi. Wraz ze wzrostem Twojej wiedzy będą rosnąć pewnie dostępy do kolejnych części systemu. Nie powinieneś się przejmować pojedynczymi błędami – uwierz że z dużym prawdopodobieństwem Twój pracodawca nadal jest na plus – ale oczywiście z błędów wyciągaj wnioski. Terminy o jakie Cię proszą dawaj z pewną dozą ostrożności. Nie wypominaj sobie pojedynczych przesunięć terminów ani nie porównuj się do kolegi obok co przyszedł 2 tyg. po Tobie a teraz jest kozakiem nad kozakami – bo pewnie wcale tak nie jest.
Osobiście uważam że osoba pracująca w modelu utrzymaniowo-rozwojowym potrzebuje znacznie więcej czasu na stanie się jednostką niezależną niż przeciętny developer. Więc uwierz że wszystko jest w porządku – wcale nie rozwijasz się wolno.
Dużo napisałem o tym co robić jak jest źle. Ale w sumie nie jest źle cały czas, więc co robić jak jest dobrze? Odpowiedź jest prosta – zawsze znajdzie się coś co zostało odłożone na później. Zawsze coś można zrobić lepiej, szybciej, zgodniej ze sztuką. Nadal pewnie jest mnóstwo rzeczy do zoptymalizowania. A jeśli pracujesz w trybie utrzymaniowo-rozwojowym – to nadal leżą nowe featurey do napisania :)
Więc.. Baw się dobrze :)
Mateusz Mazurek






